1 Concept
You have misunderstood some basic concepts, and the difficulties result from that. We have to address the concepts first, not the problem as you perceive it, and consequently, your problem will disappear.
auto incremented IDs, which are of course primary keys.
No, they are not. That is a common misconception. And problems are guaranteed to ensue.
An ID field cannot be a Primary Key in the English or technical or Relational senses.
-
Sure, in SQL, you can declare any field to be a
PRIMARY KEY, but that doesn’t magically transform it into a Primary Key in the English, technical, or Relational senses. You can name a chihuahua “Rottweiller”, but that doesn’t transform it into a Rottweiller, it remains a chihuahua. Like any language, SQL simply executes the commands that you give it, it does not understandPRIMARY KEYto mean something Relational, it just whacks an unique index on the column (or field). -
The problem is, since you have declared the
IDto be aPRIMARY KEY, you think of it as a Primary Key, and you may expect that it has some of qualities of a Primary Key. Except for the uniqueness of the ID value, it provides no benefit. It has none of the qualities of a Primary Key, or any sort of Relational Key for that matter. It is not a Key in the English, technical, or Relational senses. By declaring a non-key to be a key, you will only confuse yourself, and you will find out that there is something terribly wrong only when the user complains about duplicates in the table.
2 Relational Model
2.1 Relational tables must have row uniqueness
A PRIMARY KEY on an ID field does not provide row uniqueness. Therefore it is not a Relational table containing rows, and if it isn’t that, then it is a file containing records. It doesn’t have any of the integrity, or power (at this stage you will be aware of join power only), or speed, that a table in a Relational database has.
-
Execute this code (MS SQL) and prove it to yourself. Please do not simply read this and understand it, and then proceed to read the rest of this Answer, this code must be executed before reading further. It has curative value.
-- [1] Dumb, broken file -- Ensures unique RECORDS, allows duplicate ROWS CREATE TABLE dumb_file ( id INT IDENTITY PRIMARY KEY, name_first CHAR(30), name_last CHAR(30) ) INSERT dumb_file VALUES ( 'Mickey', 'Mouse' ), ( 'Mickey', 'Mouse' ), ( 'Mickey', 'Mouse' ) SELECT * FROM dumb_file
Notice that you have duplicate rows. Relational tables are required to have unique rows. Further proof that you do not have a relational table, or any of the qualities of one.
Notice that in your report, the only thing that is unique is the ID field, which no user cares about, no user sees, because it is not data, it is some additional nonsense that some very stupid “teacher” told you to put in every file. You have record uniqueness but not row uniqueness.
In terms of the data (the real data minus the extraneous additions), the data name_last and name_first can exist without the ID field. A person has a first name and last name without an ID being stamped on their forehead.
The second thing that you are using that confuses you is the AUTOINCREMENT. If you are implementing a record filing system with no Relational capability, sure, it is helpful, you don’t have to code the increment when inserting records. But if you are implementing a Relational Database, it serves no purpose at all, because you will never use it. There are many features in SQL that most people never use.
2.2 Corrective Action
So how do you upgrade, elevate, that dumb_file that is full of duplicate rows to a Relational table, in order to get some of the qualities and benefits of a Relational table ? There are three steps to this.
-
You need to understand Keys
And since we have progressed from ISAM files of the 1970’s, to the Relational Model, you need to understand Relational Keys. That is, if you wish to obtain the benefits (integrity, power, speed) of a Relational Database.
In Codd’s Relational Model:
a key is made up from the data
and
the rows in a table must be unique
Your “key” is not made up from the data. It is some additional, non-data parasite, caused by your being infected with the disease of your “teacher”. Recognise it as such, and allow yourself the full mental capacity that God gave you (notice that I do not ask you to think in isolated or fragmented or abstract terms, all the elements in a database must be integrated with each other).
Make up a real key from the data, and only from the data. In this case, there is only one possible Key:
(name_last, name_first). -
Try this code, declare an unique constraint on the data:
-- [2] dumb_file fixed, elevated to table, prevents duplicate rows -- still dumb CREATE TABLE dumb_table ( id INT IDENTITY PRIMARY KEY, name_first CHAR(30), name_last CHAR(30), CONSTRAINT UK UNIQUE ( name_last, name_first ) ) INSERT dumb_table VALUES ( 'Mickey', 'Mouse' ), ( 'Minnie', 'Mouse' ) SELECT * FROM dumb_table INSERT dumb_table VALUES ( 'Mickey', 'Mouse' )Now we have row uniqueness. That is the sequence that happens to most people: they create a file which allows dupes; they have no idea why dupes are appearing in the drop-downs; the user screams; they tweak the file and add an index to prevent dupes; they go to the next bug fix. (They may do so correctly or not, that is a different story.)
-
The second level. For thinking people who think beyond the fix-its. Since we have now row uniqueness, what in Heaven’s name is the purpose of the
IDfield, why do we even have it ??? Oh, because the chihuahua is named Rotty and we are afraid to touch it.The declaration that it is a
PRIMARY KEYis false, but it remains, causing confusion and false expectations. The only genuine Key there is, is the(name_last, name_fist),and it is a Alternate Key at this point.Therefore the
IDfield is totally superfluous; and so is the index that supports it; and so is the stupidAUTOINCREMENT; and so is the false declaration that it is aPRIMARY KEY; and any expectations you may have of it are false.Therefore remove the superfluous
IDfield. Try this code:-- [3] Relational Table -- Now that we have prevented duplicate data, the id field -- AND its additional index serves no purpose, it is superfluous, -- like an udder on a bull. If we remove the field AND the -- supporting index, we obtain a Relational table. CREATE TABLE relational_table ( name_first CHAR(30), name_last CHAR(30), CONSTRAINT PK PRIMARY KEY ( name_last, name_first ) ) INSERT relational_table VALUES ( 'Mickey', 'Mouse' ), ( 'Minnie', 'Mouse' ) SELECT * FROM relational_table INSERT relational_table VALUES ( 'Mickey', 'Mouse' )
Works just fine, works as intended, without the extraneous fields and indices.
Please remember this, and do it right, every single time.
2.3 False Teachers
In these end times, as advised, we will have many of them. Note well, the “teachers” who propagate ID columns, by virtue of the detailed evidence in this post, simply do not understand the Relational Model or Relational Databases. Especially those who write books about it.
As evidenced, they are stuck in pre-1970 ISAM technology. That is all they understand, and that is all that they can teach. They use an SQL database container, for the ease of Access, recovery, backup, etc, but the content is pure Record Filing System with no Relational Integrity, Power, or speed. AFAIC, it is a serious fraud.
In addition to ID fields, of course, there are several items that are key Relational-or-not concepts, that taken together, cause me to form such a grave conclusion. Those other items are beyond the scope of this post.
One particular pair of idiots is currently mounting an assault on First Normal Form. They belong in the asylum.
3 Solution
Now for the rest of your question.
3.1 Answers
Is there a way that I can create a relational table without losing auto increment features?
That is a self-contradicting sentence. I trust you will understand from my explanation, Relational tables have no need for AUTOINCREMENT “features”; if the file has AUTOINCREMENT, it is not a Relational table.
AUTOINCREMENT or IDENTITY is good for one thing only: if, and only if, you want to create an Excel spreadsheet in the SQL database container, replete with fields named A, B, and C, across the top, and record numbers down the left side. In database terms, that is the result of a SELECT, a flattened view of the data, that is not the source of data, which is organised (Normalised).
Another possible (but not preferred) solution may be there is another primary key in the first table, which is the username of the user, not with an auto increment statement, of course. Is it inevitable?
In technical work, we don’t care about preferences, because that is subjective, and it changes all the time. We care about technical correctness, because that is objective, and it does not change.
Yes, it is inevitable. Because it is just a matter of time; number of bugs; number of “can’t dos”; number of user screams, until you face the facts, overcome your false declarations, and realise that:
-
the only way to ensure that user rows are unique, that user_names are unique, is to declare an
UNIQUEconstraint on it -
and get rid of
user_idoridin the user file -
which promotes
user_nametoPRIMARY KEY
Yes, because your entire problem with the third table, not coincidentally, is then eliminated.
That third table is an Associative Table. The only Key required (Primary Key) is a composite of the two parent Primary Keys. That ensures uniqueness of the rows, which are identified by their Keys, not by their IDs.
I am warning you about that because the same “teachers” who taught you the error of implementing ID fields, teach the error of implementing ID fields in the Associative Table, where, just as with an ordinary table, it is superfluous, serves no purpose, introduces duplicates, and causes confusion. And it is doubly superfluous because the two keys that provide are already there, staring us in the face.
Since they do not understand the RM, or Relational terms, they call Associative Tables “link” or “map” tables. If they have an ID field, they are in fact, files.
3.2 Lookup Tables
ID fields are particularly Stupid Thing to Do for Lookup or Reference tables. Most of them have recognisable codes, there is no need to enumerate the list of codes in them, because the codes are (should be) unique.
ENUM is just as stupid, but for a different reason: it locks you into an anti-SQL method, a “feature” in that non-compliant “SQL”.
Further, having the codes in the child tables as FKs, is a Good Thing: the code is much more meaningful, and it often saves an unnecessary join:
SELECT ...
FROM child_table -- not the lookup table
WHERE gender_code = "M" -- FK in the child, PK in the lookup
instead of:
SELECT ...
FROM child_table
WHERE gender_id = 6 -- meaningless to the maintainer
or worse:
SELECT ...
FROM child_table C -- that you are trying to determine
JOIN lookup_table L
ON C.gender_id = L.gender_id
WHERE L.gender_code = "M" -- meaningful, known
Note that this is something one cannot avoid: you need uniqueness on the lookup code and uniqueness on the description. That is the only method to prevent duplicates in each of the two columns:
CREATE TABLE gender (
gender_code CHAR(2) NOT NULL,
name CHAR(30) NOT NULL
CONSTRAINT PK
PRIMARY KEY ( gender_code )
CONSTRAINT AK
UNIQUE ( name )
)
3.3 Full Example
From the details in your question, I suspect that you have SQL syntax and FK definition issues, so I will give the entire solution you need as an example (since you have not given file definitions):
CREATE TABLE user ( -- Typical Identifying Table
user_name CHAR(16) NOT NULL, -- Short PK
name_first CHAR(30) NOT NULL, -- Alt Key.1
name_last CHAR(30) NOT NULL, -- Alt Key.2
birth_date DATE NOT NULL -- Alt Key.3
CONSTRAINT PK -- unique user_name
PRIMARY KEY ( user_name )
CONSTRAINT AK -- unique person identification
PRIMARY KEY ( name_last, name_first, birth_date )
)
CREATE TABLE sport ( -- Typical Lookup Table
sport_code CHAR(4) NOT NULL, -- PK Short code
name CHAR(30) NOT NULL -- AK
CONSTRAINT PK
PRIMARY KEY ( sport_code )
CONSTRAINT AK
PRIMARY KEY ( name )
)
CREATE TABLE user_sport ( -- Typical Associative Table
user_name CHAR(16) NOT NULL, -- PK.1, FK
sport_code CHAR(4) NOT NULL, -- PK.2, FK
start_date DATE NOT NULL
CONSTRAINT PK
PRIMARY KEY ( user_name, sport_code )
CONSTRAINT user_plays_sport_fk
FOREIGN KEY ( user_name )
REFERENCES user ( user_name )
CONSTRAINT sport_occupies_user_fk
FOREIGN KEY ( sport_code )
REFERENCES sport ( sport_code )
)
There, the PRIMARY KEY declaration is honest, it is a Primary Key; no ID; no AUTOINCREMENT; no extra indices; no duplicate rows; no erroneous expectations; no consequential problems.
3.4 Relational Data Model
Here is the Data Model to go with the definitions.
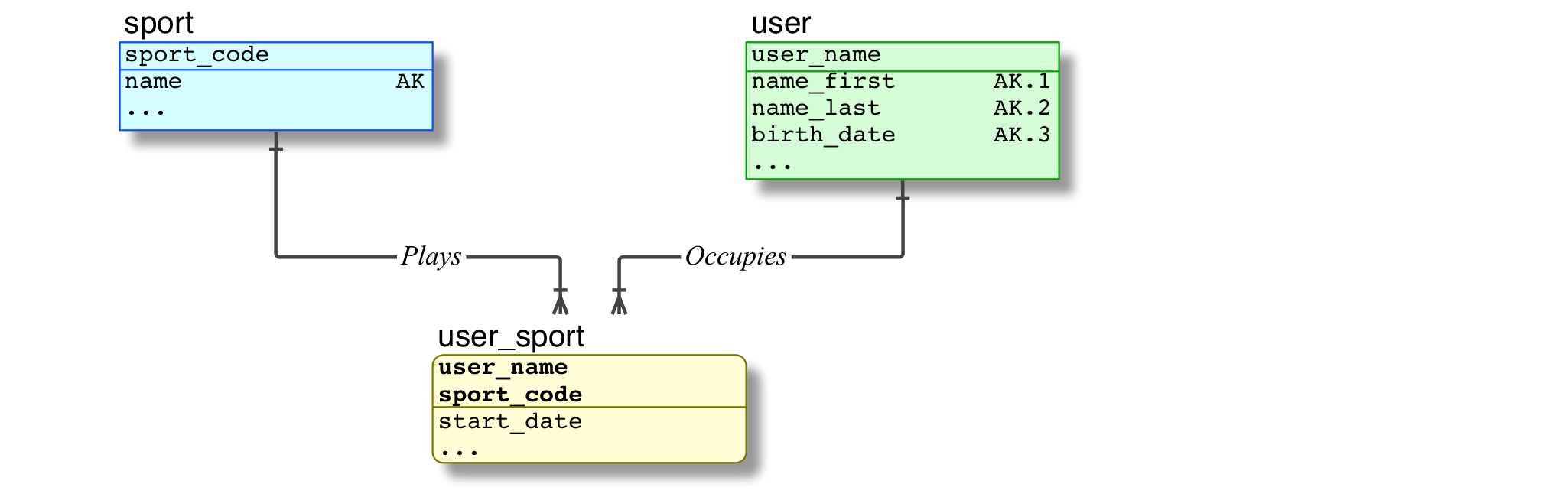
-
As a PDF
-
If you are not used to the Notation, please be advised that every little tick, notch, and mark, the solid vs dashed lines, the square vs round corners, means something very specific. Refer to the IDEF1X Notation.
-
A picture is worth a thousand words; in this case a standard-complaint picture is worth more than that; a bad one is not worth the paper it is drawn on.
-
Please check the Verb Phrases carefully, they comprise a set of Predicates. The remainder of the Predicates can be determined directly from the model. If this is not clear, please ask.